Pierre-Yves Oudeyer
Artificial Intelligence, Machine Learning, Cognitive Science
Emotional Speech Synthesis and Recognition
Emotional speech synthesis
I have been working on algorithms for emotional speech synthesis. The objective was to manipulate the prosody of computer generated speech signals so that a human listener can perceive different kinds of emotions or attitudes, such as happiness, sadness or anger. The algorithms that I developped were inspired by psychoacoustic studies but in no way tryed to reproduce precisely the way humans modulate their prosody to express emotions. Rather, I developed operators for prosodic deformation which are analogous to the deformation of faces in Walt Disney pictures used to express visually the emotions of characters. In brief, there was little science in this project, but a lot of fun!
These algorithms are described in:
Oudeyer P-Y. (2003) The production and recognition of emotions in speech: features and algorithms, International Journal in Human-Computer Studies , 59(1-2), pp. 157–183, special issue on Affective Computing. Bibtex
You can hear yourself some examples of results in the following baby-like meaningless babbling sounds:
 Neutral:
Neutral: Happy:
Happy:
 Angry :
Angry :
Also, I developped means to control continuously the degree of emotion as well as the age of the voice, as seen on the following screenshot of our software :
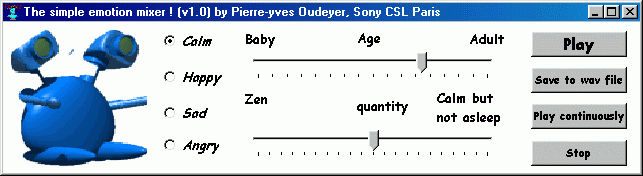
happy, but not so much normally happy very happy
sad, but not so much normally sad very sad
angry, but not so much normally angry very angry
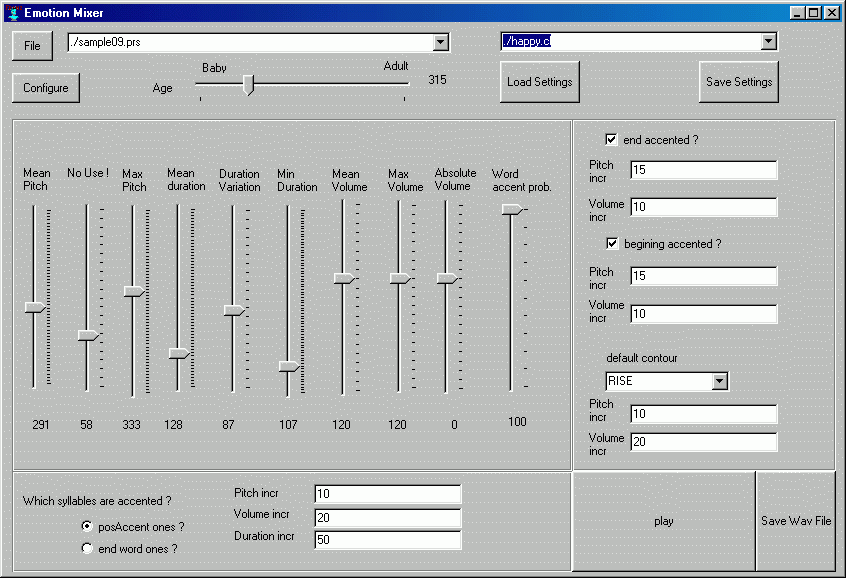
I applyed these algorithm to meaningful speech, and in particular to japanese speech.
Here is a screenshot of the corresponding software, in which you can see lower level controls than on the previous software) :
Related project:
 The Maïdo and Gurby Experiment is a particular setup showing how autonomous creatures can coordinate socially to build a shared repertoire of syllables. Social coordination is achieved through the modulation of prosody in babbling sounds, which allows creatures to convey basic attitudes and emotionn.
The Maïdo and Gurby Experiment is a particular setup showing how autonomous creatures can coordinate socially to build a shared repertoire of syllables. Social coordination is achieved through the modulation of prosody in babbling sounds, which allows creatures to convey basic attitudes and emotionn.
Contact Info
ERC Grant Explorers
![]()
My research is partially funded by an ERC Starting Grant (project EXPLORERS) from the European Research Council.